¿Qué es un Docker? (Post N° 2)


Docker es la plataforma de contenedor más utilizada en la actualizada, la cual permite la creación, ejecución y la gestión de contenedores. Los contenedores son entornos ligeros y portátiles, que empaquetan todo lo necesario para la ejecución de una aplicación, incluyendo código, librerías y dependencia. Los contenedores permiten construir código que puede ser ejecutando en cualquier maquina, sin importar dependencias del entorno o configuraciones de sistema.
¿Por qué usar Docker?
Docker es una herramienta bastante importante en el desarrollo de software, la cual se puede usar para distintas tareas, tales como:
-
- Desarrollo de aplicaciones: Docker entrega un entorno consistente para el desarrollo y pruebas de aplicaciones, generando un entorno de producción estable, reduciendo los problemas de compatibilidad e integración.
-
- Micro servicios: Docker es ideal en instalación de micro servicios, ya que las aplicaciones pueden ejecutarse independiente una de la otra, ejecutándose en sus propios contenedores. En este caso, los modelos de machine learning pueden ser construidos como micro servicios, tanto para su entrenamiento como inferencia.
¿Qué archivos son claves para desplegar un Docker?
Para construir y desplegar un contenedor dentro de un docker, se deben considerar tres principales archivos:
-
- Dockerfile: Este archivo posiblemente es el más importante en cualquier proyecto que utilice contenedor usando docker. Este archivo contiene una serie de instrucciones a seguir para construir la imagen del docker, desde la base, comando, copiar archivos hasta variables de entorno.
-
- Dockerignore: Su función es determinar que elementos se deben ignorar al momento de ejecutar o construir la imagen.
-
- Requestment.txt: Su función es declarar que librerías se deben instalar al momento de construir la imagen Docker.
Ejemplo Práctico: ¿Cómo construir un API de Whisper usando Docker?
Este endpoint permitirá transcribir un audio a texto, entregando el texto como resultado, más el tiempo en ejecución. Adicionalmente, construiré este docker en una máquina virtual en GCP con GPU, aplicando comandos para instalar Docker dentro de la VM, junto con comparar el rendimiento entre la velocidad de transcripción usando GPU y no tenerla. Nota: Toda esta información se encuentra en el siguiente repositorio: -
DockerFile
Inicialmente, se construyó un dockerfile, que contiene la siguiente información:
from azure.core.exceptions import HttpResponseError
article_df["id"] = article_df["id"].astype(str)
article_df["vector_id"] = article_df["vector_id"].astype(str)
# Convert the DataFrame to a list of dictionaries
documents = article_df.to_dict(orient="records")
# Create a SearchIndexingBufferedSender
batch_client = SearchIndexingBufferedSender(
search_service_endpoint, index_name, credential
)
try:
# Add upload actions for all documents in a single call
batch_client.upload_documents(documents=documents)
# Manually flush to send any remaining documents in the buffer
batch_client.flush()
except HttpResponseError as e:
print(f"An error occurred: {e}")
finally:
# Clean up resources
batch_client.close()
print(f"Uploaded {len(documents)} documents in total")
Como se mencionó anteriormente, el docker es una secuencia de instrucciones. En este caso, su linea base es una imagen nvidia con CUDA instalado. Posteriormente, se instalan paquetes necesarios para que se ejecute whisper dentro del contenedor (ffmpeg). Además, contiene el comando CMD, que al iniciar el contenedor, Docker ejecutará automáticamente el comando para arrancar el servidor Uvicorn con una aplicación FastAPI.
¿Qué contiene la API?
La API es capaz de recibir un archivo mp3 o un conjunto de archivos, procesarlos por el modelo de whisper para su transcripción, devolviendo un json como resultado. Para separar la transcripción del archivo main, se construyó un archivo serviceswhisper.py, el cual contiene la llamada al modelo de whisper y su ejecución. Este archivo es simple, ya que llama al modelo, construye un archivo temporal el mp3, para luego introducirlo a whisper, y retornar el texto.
¿Cómo desplegar el docker en un VM?
Para desplegar la API, se utilizó una VM en Google para construir la imagen y ejecutar el contenedor. Google tiene maquinas con imágenes pre-instaladas de Deeplearning y drivers de NVIDIA, facilitando enormemente la ejecución de contenedores usando GPU.Para este propósito, usando mi cuenta de GPC, en la sección de Enginer Computer, alquile una maquina con GPU (Nvidia T4), con un sistema operativo “Deep Learning On Linux” (imagen). Esta maquina cuesta alrededor de 200 dólares mensuales, pero como la utilice aproximadamente una hora para este ejercicio, no fue mayor gasto.
Al instalar la maquina y conectarse por SSH al terminal, se puede comprobar que los driver de NVIDIA están instalados, ejecutando el siguiente comando en su terminal:
nvidia-smi
Si no hay ningún error en el terminal, debería aparecer una imagen parecida a la siguiente:
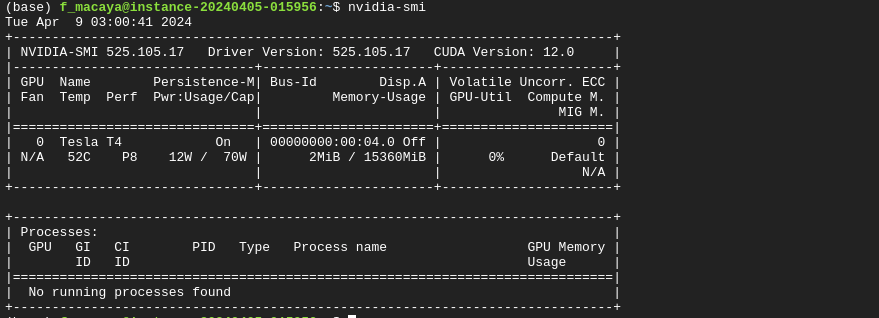
Esta imagen demuestra que los driver de NVIDIA están instalados en la maquina, siendo capaz de ejecutar códigos que requieran GPU. Después, se debe instalar docker en la maquina, siguiendo los pasos descrito en el Github del repositorio. (Github ).
Para construir la imagen docker, se puede utilizar el siguiente comando:
docker build -t whisper .
Finalmente, se debe ejecutar la imagen del contenedor previamente construida. Si se requiere ejecutar con la GPU de la maquina virtual, se debe utilizar el siguiente comando:
docker run --gpus all -p 8000:80 whisper
No obstante, si requiere ejecutar sin ella, se utiliza:
docker run -p 8000:80 whisper
Independiente de la forma de ejecutar el docker, se levantará un endpoint llamado api/whisper en el puerto 8000. Este endpoint puede ser accesible desde la misma maquina u otra de afuera de GCP configurando las reglas de firewall, mediante la creación de una nueva regla de Firewall, que permita poder acceder al puerto 8000 desde cualquier instancia en Google.
Dentro del github se encuentra un audio llamado audio.mp3, el cual tiene una duración alrededor de 15 minutos, y puede ser usado para la transcripción. El endpoint puede ser validado utilizado el siguiente código:
url = 'http://Externa IP:8000/api/whisper'
files = {'files': ('filename.mp3', open('audio.mp3', 'rb'), 'audio/mpeg')}
response = requests.post(url, files=files)
Al ejecutar el código usando el comando con “–-gpu”, el tiempo de transcripción es de 45 segundos. No obstante, si se ejecuta sin gpu, el tiempo es de 190 segundos aprox, representando una aumento de un 422% respecto a tener tarjeta gráfica.